Discuss Scratch
- Discussion Forums
- » Advanced Topics
- » ~tosh~ public beta
![[RSS Feed]](//cdn.scratch.mit.edu/scratchr2/static/__74e70580e9dbe93ce1c3f8422dde592d__//djangobb_forum/img/feed-icon-small.png "[RSS Feed]")
- gtoal
-
 Scratcher
Scratcher

1000+ posts
~tosh~ public beta
Static recompilation for the NES has some… interesting challenges. http://andrewkelley.me/post/jamulator.html explored this in great detail, although a few of his challenges are not so; see my response: https://rosenzweig.io/solving-bit-magic.html
Actually that's an easy one. You decompile and generate code from any code start address *even if this means generating two sequences which overlap*.
You label and decompile from the Bit# instruction, as well as from the instruction that starts in the middle of its operand. At some point the code synchs up again, and you just get the ex-bedded sequence to jump to the common address from the inline code, and you're back in business.
I've done quite a bit of this in the past. I was part of a small group that wrote a multi-source/multi-target translator - we wrote our own intermediate structure in the style of LLVM but in hindsight we should have used LLVM itself. It would have been a lot easier than writing all the code to handle Phi-nodes etc from scratch. We didn't know much about LLVM at the time. If you ever feel like doing serious work in this area do get in touch and we can give you a head start with the work we've already done which was quite extensive.
There are very few instances where a fallback interpreter is needed, though it is nice to have and comes in very useful in the early stages when you are still determining the code flow, so you might as well have one anyway.
Graham
- bobbybee
-
 Scratcher
Scratcher

1000+ posts
~tosh~ public beta
Actually that's an easy one. You decompile and generate code from any code start address *even if this means generating two sequences which overlap*.Yes, that's the solution I described I think. Oh well, discovering things for yourself is fun :-)
You label and decompile from the Bit# instruction, as well as from the instruction that starts in the middle of its operand. At some point the code synchs up again, and you just get the ex-bedded sequence to jump to the common address from the inline code, and you're back in business.
I've done quite a bit of this in the past. I was part of a small group that wrote a multi-source/multi-target translator - we wrote our own intermediate structure in the style of LLVM but in hindsight we should have used LLVM itself. It would have been a lot easier than writing all the code to handle Phi-nodes etc from scratch. We didn't know much about LLVM at the time. If you ever feel like doing serious work in this area do get in touch and we can give you a head start with the work we've already done which was quite extensive.
Sounds impressive :-) Thank you, although I'm not sure I do serious work in any area these days

There are very few instances where a fallback interpreter is needed, though it is nice to have and comes in very useful in the early stages when you are still determining the code flow, so you might as well have one anyway.
How do you generically handle jump tables? I suppose with a sufficiently sophisticated algebra system, you could prove something clever directly*, but there has to be something in between that and hardcoding the pattern!
* Given the line “PC := ROM(C + X)”, derive, uh, { PC | PC ∈ ROM(C + X) ∀ X : X ∈ ℤ, X < 2^8 }. The problem seems even harder the more I think about it… if X is 16-bits suddenly you go up to 65536 addresses to add. Hmph.
Last edited by bobbybee (Jan. 24, 2017 00:04:02)
“Ooo, can I call you Señorita Bee?” ~Chibi-Matoran
- gtoal
-
Scratcher
1000+ posts
~tosh~ public beta
How do you generically handle jump tables? I suppose with a sufficiently sophisticated algebra system, you could prove something clever directly*, but there has to be something in between that and hardcoding the pattern!
* Given the line “PC := ROM(C + X)”, derive, uh, { PC | PC ∈ ROM(C + X) ∀ X : X ∈ ℤ, X < 2^8 }. The problem seems even harder the more I think about it… if X is 16-bits suddenly you go up to 65536 addresses to add. Hmph.
There's the way we actually got away with doing, and the way we would do it if being pedantic and guaranteeing success for the 1% of cases that the simple method fails for.
What we actually did was playtest any particular rom intensively, so that we either invoked every path in the code, or executed blocks with clear branches to code that could be discovered with a spidering disassembler, which we supplemented with semi-manual-assisted identification of jump tables in a very few cases. This was sufficient for every rom we looked at.
However given that you have a fallback interpreter, the backup plan is to start interpreting when you hit a dynamic jump that wasn't previously compiled. Then when the interpretation hits an address that is the start of a basic block, resume the compiled code.
BUT here's where it gets clever… remember the trick with the Bit# instruction? where you have two separate paths through that byte, one where it is treated as the operand of the Bit# instruction and another where it is an opcode in its own right? Well, you generate a version of the entire program where you generate code starting at every byte… these sequences will be short and quickly terminate as soon as you get to an address that is the start of a basic block. So in fact at the cost of some redundancy (no greater than 3X for most 16-bit address micros) you can actually have a compiled fallback option rather than an interpreter. Though if there's a chance of code being generated on the fly in RAM then you still need the interpreter to handle the dynamic code. (Does happen in a few games where custom bitbit blocks are generated)
Anyway the point of the above is that if you jump to a random address, you've already compiled whatever the code is at that address, even if you didn't already believe it was in fact code. Your normal path through the code optimises basic blocks and therefore will have large stretches with no jump label destinations (because the mapping of input code to output code isn't 1:1 at the instruction level, only functionally equivalent at the entire basic block level) but the backup code you created on byte boundaries *does* have target label entries not only for each valid instruction but also for the invalid sequences that start in the middle of instructions, just in case. These sequences drop through rather than returning to the interpreter loop, but they terminate at the end of basic blocks where you can jump back into the ‘fast’ version of the code that is optimised at the block level. Every instruction in these sequences supports a jump destination entry.
(the optimised blocks elide about 90% of the instructions - usually losing just about all but the last settings of the internal flags - redundant load and dead store optimisations predominate the savings)
Note that any jump targets that are not already in the optimised code path are recorded, and used in the next run of generating the translation. So the scheme above is not in fact the exception for awkward cases, it is the default behaviour from the first run onwards as it is how you build your jump destination tables in the first place.
Graham
Last edited by gtoal (Jan. 24, 2017 01:48:54)
- IcyCoder
-
 Scratcher
Scratcher

1000+ posts
~tosh~ public beta
Shouldnt this go in this project @bobbybee is talking about's offical forum.How do you generically handle jump tables? I suppose with a sufficiently sophisticated algebra system, you could prove something clever directly*, but there has to be something in between that and hardcoding the pattern!
* Given the line “PC := ROM(C + X)”, derive, uh, { PC | PC ∈ ROM(C + X) ∀ X : X ∈ ℤ, X < 2^8 }. The problem seems even harder the more I think about it… if X is 16-bits suddenly you go up to 65536 addresses to add. Hmph.
There's the way we actually got away with doing, and the way we would do it if being pedantic and guaranteeing success for the 1% of cases that the simple method fails for.
What we actually did was playtest any particular rom intensively, so that we either invoked every path in the code, or executed blocks with clear branches to code that could be discovered with a spidering disassembler, which we supplemented with semi-manual-assisted identification of jump tables in a very few cases. This was sufficient for every rom we looked at.
However given that you have a fallback interpreter, the backup plan is to start interpreting when you hit a dynamic jump that wasn't previously compiled. Then when the interpretation hits an address that is the start of a basic block, resume the compiled code.
BUT here's where it gets clever… remember the trick with the Bit# instruction? where you have two separate paths through that byte, one where it is treated as the operand of the Bit# instruction and another where it is an opcode in its own right? Well, you generate a version of the entire program where you generate code starting at every byte… these sequences will be short and quickly terminate as soon as you get to an address that is the start of a basic block. So in fact at the cost of some redundancy (no greater than 3X for most 16-bit address micros) you can actually have a compiled fallback option rather than an interpreter. Though if there's a chance of code being generated on the fly in RAM then you still need the interpreter to handle the dynamic code. (Does happen in a few games where custom bitbit blocks are generated)
Anyway the point of the above is that if you jump to a random address, you've already compiled whatever the code is at that address, even if you didn't already believe it was in fact code. Your normal path through the code optimises basic blocks and therefore will have large stretches with no jump label destinations (because the mapping of input code to output code isn't 1:1 at the instruction level, only functionally equivalent at the entire basic block level) but the backup code you created on byte boundaries *does* have target label entries not only for each valid instruction but also for the invalid sequences that start in the middle of instructions, just in case. These sequences drop through rather than returning to the interpreter loop, but they terminate at the end of basic blocks where you can jump back into the ‘fast’ version of the code that is optimised at the block level. Every instruction in these sequences supports a jump destination entry.
(the optimised blocks elide about 90% of the instructions - usually losing just about all but the last settings of the internal flags - redundant load and dead store optimisations predominate the savings)
Note that any jump targets that are not already in the optimised code path are recorded, and used in the next run of generating the translation. So the scheme above is not in fact the exception for awkward cases, it is the default behaviour from the first run onwards as it is how you build your jump destination tables in the first place.
Graham
Because JS is the future (echos) future future futur futu fut fu f
- bobbybee
-
Scratcher
1000+ posts
~tosh~ public beta
Makes sense; thanks :-)How do you generically handle jump tables? I suppose with a sufficiently sophisticated algebra system, you could prove something clever directly*, but there has to be something in between that and hardcoding the pattern!
* Given the line “PC := ROM(C + X)”, derive, uh, { PC | PC ∈ ROM(C + X) ∀ X : X ∈ ℤ, X < 2^8 }. The problem seems even harder the more I think about it… if X is 16-bits suddenly you go up to 65536 addresses to add. Hmph.
There's the way we actually got away with doing, and the way we would do it if being pedantic and guaranteeing success for the 1% of cases that the simple method fails for.
What we actually did was playtest any particular rom intensively, so that we either invoked every path in the code, or executed blocks with clear branches to code that could be discovered with a spidering disassembler, which we supplemented with semi-manual-assisted identification of jump tables in a very few cases. This was sufficient for every rom we looked at.
However given that you have a fallback interpreter, the backup plan is to start interpreting when you hit a dynamic jump that wasn't previously compiled. Then when the interpretation hits an address that is the start of a basic block, resume the compiled code.
BUT here's where it gets clever… remember the trick with the Bit# instruction? where you have two separate paths through that byte, one where it is treated as the operand of the Bit# instruction and another where it is an opcode in its own right? Well, you generate a version of the entire program where you generate code starting at every byte… these sequences will be short and quickly terminate as soon as you get to an address that is the start of a basic block. So in fact at the cost of some redundancy (no greater than 3X for most 16-bit address micros) you can actually have a compiled fallback option rather than an interpreter. Though if there's a chance of code being generated on the fly in RAM then you still need the interpreter to handle the dynamic code. (Does happen in a few games where custom bitbit blocks are generated)
Anyway the point of the above is that if you jump to a random address, you've already compiled whatever the code is at that address, even if you didn't already believe it was in fact code. Your normal path through the code optimises basic blocks and therefore will have large stretches with no jump label destinations (because the mapping of input code to output code isn't 1:1 at the instruction level, only functionally equivalent at the entire basic block level) but the backup code you created on byte boundaries *does* have target label entries not only for each valid instruction but also for the invalid sequences that start in the middle of instructions, just in case. These sequences drop through rather than returning to the interpreter loop, but they terminate at the end of basic blocks where you can jump back into the ‘fast’ version of the code that is optimised at the block level. Every instruction in these sequences supports a jump destination entry.
(the optimised blocks elide about 90% of the instructions - usually losing just about all but the last settings of the internal flags - redundant load and dead store optimisations predominate the savings)
Note that any jump targets that are not already in the optimised code path are recorded, and used in the next run of generating the translation. So the scheme above is not in fact the exception for awkward cases, it is the default behaviour from the first run onwards as it is how you build your jump destination tables in the first place.
Graham
“Ooo, can I call you Señorita Bee?” ~Chibi-Matoran

- mobluse
-
 Scratcher
Scratcher

100+ posts
~tosh~ public beta
I have a new feature request for Tosh: When you press Ctrl+F (find) in Tosh you have to fill in what you search for again if you have edited in between. It would be more comfortable if the search term was the same as the last one. This would work the same way as in common browsers, i.e. the search term would be marked so that you can easily replace it with a new one.
My browser / operating system: Windows NT 10.0, Chrome 55.0.2883.87, Flash 24.0 (release 0)
My browser / operating system: Windows NT 10.0, Chrome 55.0.2883.87, Flash 24.0 (release 0)




- mobluse
-
Scratcher
100+ posts
~tosh~ public beta
For a few days now on https://tosh.tjvr.org/app/ some buttons are invisible, e.g. those for starting and stopping, and changing name or removing sprites. You can still click where they were, and that works, but I guess it's difficult for beginners.
Another probably unrelated issue: There is one project I can't load in Tosh: https://scratch.mit.edu/projects/116467374/
It is possible to load this project in Scratch 2 Offline Editor.
My browser / operating system: Windows NT 10.0, Chrome 55.0.2883.87, Flash 24.0 (release 0)
Another probably unrelated issue: There is one project I can't load in Tosh: https://scratch.mit.edu/projects/116467374/
It is possible to load this project in Scratch 2 Offline Editor.
My browser / operating system: Windows NT 10.0, Chrome 55.0.2883.87, Flash 24.0 (release 0)

- mobluse
-
Scratcher
100+ posts
~tosh~ public beta
I tried this now and it didn't help. I also cleared the cache in other browsers, but the buttons are missing.some buttons are invisibleTry clearing your cache?

Chrome: My browser / operating system: Windows NT 10.0, Chrome 56.0.2924.87, Flash 24.0 (release 0)
Firefox: My browser / operating system: Windows NT 10.0, Firefox 47.0, Flash 21.0 (release 0)
Edge: My browser / operating system: Windows NT 10.0, Chrome 52.0.2743.116, Flash 24.0 (release 0)
IE: My browser / operating system: Windows NT 10.0, Microsoft Internet Explorer 11.0, Flash 24.0 (release 0)
I have also tested it before with browsers in most updated PIXEL (Raspbian) and Lubuntu 16.04 on Raspberry Pi, but they also miss the buttons.
Chrome: My browser / operating system: Linux, Chrome 56.0.2924.84, Flash 11.2 (release 999)
Firefox: My browser / operating system: Ubuntu Linux, Firefox 52.0, No Flash version detected
Do you see the buttons? Which OS and browser are you using?
Last edited by mobluse (March 17, 2017 19:57:53)
- IcyCoder
-
Scratcher
1000+ posts
~tosh~ public beta
Screenshots?I tried this now and it didn't help. I also cleared the cache in other browsers, but the buttons are missing.some buttons are invisibleTry clearing your cache?
Chrome: My browser / operating system: Windows NT 10.0, Chrome 56.0.2924.87, Flash 24.0 (release 0)
Firefox: My browser / operating system: Windows NT 10.0, Firefox 47.0, Flash 21.0 (release 0)
Edge: My browser / operating system: Windows NT 10.0, Chrome 52.0.2743.116, Flash 24.0 (release 0)
IE: My browser / operating system: Windows NT 10.0, Microsoft Internet Explorer 11.0, Flash 24.0 (release 0)
I have also tested it before with browsers in most updated PIXEL (Raspbian) and Lubuntu 16.04 on Raspberry Pi, but they also miss the buttons.
Do you see the buttons? Which OS and browser are you using?

Because JS is the future (echos) future future futur futu fut fu f
- mobluse
-
Scratcher
100+ posts
~tosh~ public beta
I have a screenshot now. I don't know how to upload screenshots to Scratch. I need to upload it somewhere else and paste the link. Is there a site where I can upload an image that's OK with Scratch?Screenshots?Do you see the buttons? Which OS and browser are you using?some buttons are invisibleTry clearing your cache?
BTW Can you see the buttons on http://tosh.tjvr.org/app/ ? Which OS and browser are you using?
If others also cannot see the buttons then I should not need to upload a screenshot.
Last edited by mobluse (Feb. 20, 2017 13:34:19)

- mobluse
-
Scratcher
100+ posts
~tosh~ public beta
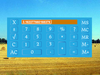
cubeupload.com is a safe image hostHere is a screenshot from PIXEL (a.k.a. Raspbian) on Raspberry Pi of http://tosh.tjvr.org/app/ :

The buttons above the stage and on the sprites in the list below are missing. It looks the same in the other OS:s and browsers I've tested.
- BookOwl
-
 Scratcher
Scratcher

1000+ posts
~tosh~ public beta
Open the developer console and see if there are any errors showing.
who needs signatures
- blob8108
-
 Scratcher
Scratcher
1000+ posts
~tosh~ public beta
Where are you—at home? Is something messing with the network request to get the icons? Maybe a proxy or cache or content filter?
I see them fine, and I can't figure out why you'd have problems seeing the icons in all those different browsers.
I see them fine, and I can't figure out why you'd have problems seeing the icons in all those different browsers.
- TastyLittleMuffin
-
 Scratcher
Scratcher

77 posts
~tosh~ public beta
Really cool! I keep trying to code in Javascript because that's what I'm used to.

- herohamp
-
 Scratcher
Scratcher
1000+ posts
~tosh~ public beta
I wish it would be open source then I would make a javascript to tosh to scratch
- -stache-
-
 Scratcher
Scratcher

500+ posts
~tosh~ public beta
I wish it would be open source then I would make a javascript to tosh to scratch…
3x3 pb: 13.240
3x3 avg: ~21-26
- birdoftheday
-
 Scratcher
Scratcher

500+ posts
~tosh~ public beta
I wish it would be open source then I would make a javascript to tosh to scratchYou can still do that. Just write a thing to convert text into scratchblock json, and put it into a project…
Am I the only person who likes 3.0 better than 2.0, or do the people who do just not talk about it?