Discuss Scratch

- Discussion Forums
- » Advanced Topics
- » uploads.scratch.mit.edu for scratch-www pages?
![[RSS Feed]](//cdn.scratch.mit.edu/scratchr2/static/__5b3e40ec58a840b41702360e9891321b__//djangobb_forum/img/feed-icon-small.png "[RSS Feed]")
- dhuls
-
 Scratcher
Scratcher

1000+ posts
uploads.scratch.mit.edu for scratch-www pages?
THIS IS NOT A SUGGESTION. THIS IS A QUESTION
You know how uploads.scratch.mit.edu serves as a mirror for scratchr2 pages. It works when the main website is under maintenance mode. Is there anything like it for scratch-www pages? uploads simply gives out an error for scratch-www pages.
- dhuls
-
Scratcher
1000+ posts
uploads.scratch.mit.edu for scratch-www pages?
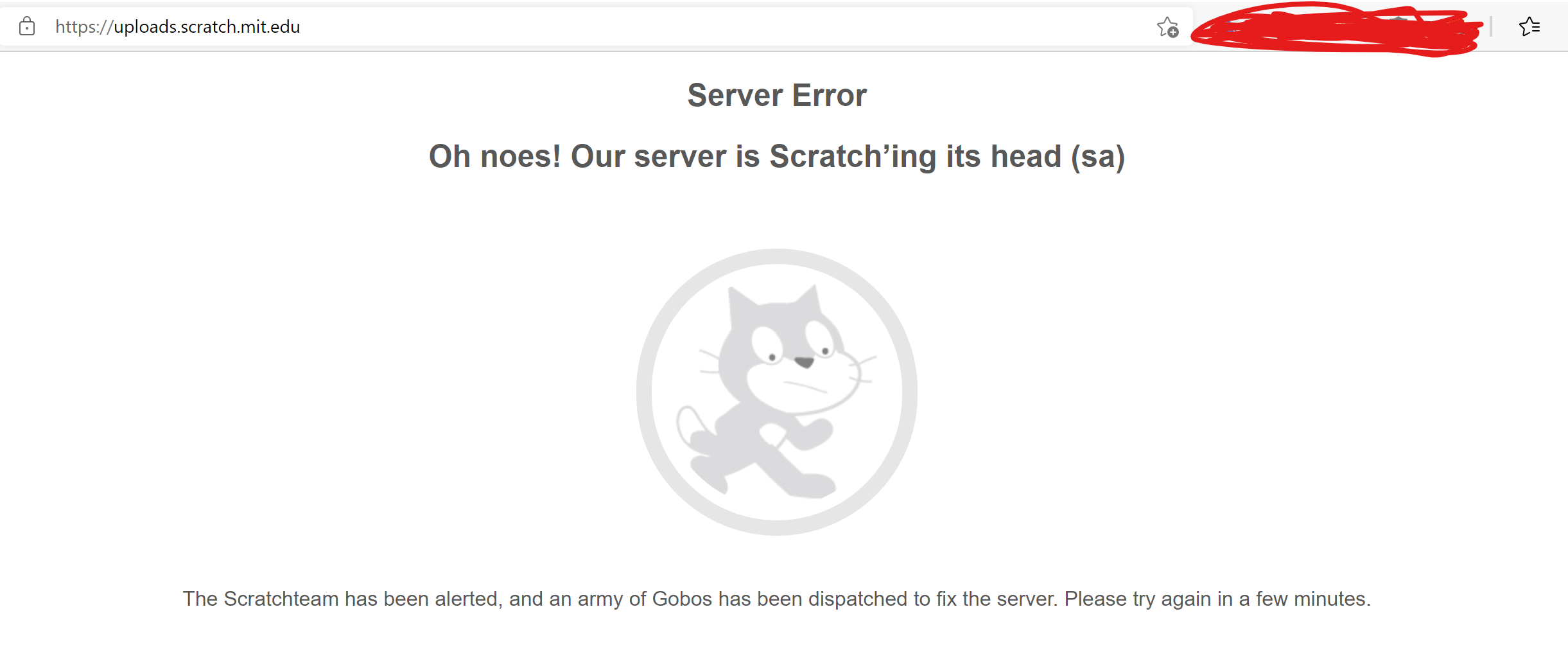
What happens when you try to view the front page with uploads.scratch.mit.edu
(posted with uploads.scratch.mit.edu)
- gdpr70f61245d597c25631fbb669
-
 Scratcher
Scratcher

100+ posts
uploads.scratch.mit.edu for scratch-www pages?
The version for scratch-www pages is scratch.mit.edu
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
- Jeffalo
-
 Scratcher
Scratcher

1000+ posts
uploads.scratch.mit.edu for scratch-www pages?
The version for scratch-www pages is scratch.mit.edui don't think that's how it works.
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
they've got some kind of config at fastly or their servers, which sends all traffic to scratchr2 except for paths that exist as scratch-www pages.
uploads is for pictures and stuff, and i guess it's meant to be faster at serving them.
- gdpr70f61245d597c25631fbb669
-
Scratcher
100+ posts
uploads.scratch.mit.edu for scratch-www pages?
The version for scratch-www pages is scratch.mit.edui don't think that's how it works.
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
they've got some kind of config at fastly or their servers, which sends all traffic to scratchr2 except for paths that exist as scratch-www pages.
One of the startup options for scratch-www is “FALLBACK” which is described as “Pass-through location for old site”. You can set this to "https://uploads.scratch.mit.edu“ to have all scratchr2 pages work. Not setting them will cause all pages not on scratch-www to return something like ”Cannot GET /discuss" (as is the standard express error).
- Jeffalo
-
Scratcher
1000+ posts
uploads.scratch.mit.edu for scratch-www pages?
yeah but thats a hack we can do to get it to work. i might be wrong, but i doubt they use that in their production (or even development/staging) systems.The version for scratch-www pages is scratch.mit.edui don't think that's how it works.
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
they've got some kind of config at fastly or their servers, which sends all traffic to scratchr2 except for paths that exist as scratch-www pages.
One of the startup options for scratch-www is “FALLBACK” which is described as “Pass-through location for old site”. You can set this to "https://uploads.scratch.mit.edu“ to have all scratchr2 pages work. Not setting them will cause all pages not on scratch-www to return something like ”Cannot GET /discuss" (as is the standard express error).
- gdpr70f61245d597c25631fbb669
-
Scratcher
100+ posts
uploads.scratch.mit.edu for scratch-www pages?
I do know that when scratch-www was first in development and scratchr2 was on scratch.mit.edu , scratch-www pages was scratchr2 querying staging.scratch.mit.edu (with the API being at api-staging.scratch.mit.edu).yeah but thats a hack we can do to get it to work. i might be wrong, but i doubt they use that in their production (or even development/staging) systems.The version for scratch-www pages is scratch.mit.edui don't think that's how it works.
scratch-www is running on scratch.mit.edu, and when a page there does not exist it queries uploads.scratch.mit.edu
they've got some kind of config at fastly or their servers, which sends all traffic to scratchr2 except for paths that exist as scratch-www pages.
One of the startup options for scratch-www is “FALLBACK” which is described as “Pass-through location for old site”. You can set this to "https://uploads.scratch.mit.edu“ to have all scratchr2 pages work. Not setting them will cause all pages not on scratch-www to return something like ”Cannot GET /discuss" (as is the standard express error).
Now that api-staging.scratch.mit.edu is now at api.scratch.mit.edu, it is not unreasonable to assume the main domain has been reversed as well, with the scratch-www at scratch.mit.edu querying another domain.
As for why the scratchr2 domain would be called “uploads”….I'm not sure. It could be a dual purpose.
If it is being rerouted from Fastly then I'd like to know: 1) What the purpose of FALLBACK is 2) What the deal is with URLs like https://scratch.mit.edu/community_guidelinesasdfoi signing users out (this would be more likely to happen if it was proxying from scratch-www itself and not through Fastly)
- Discussion Forums
- » Advanced Topics
-
» uploads.scratch.mit.edu for scratch-www pages?